Je vous connais ! Ça fait des mois que vos bitcoins traînent sur un échange ou une appli mobile. Toutes les semaines, vous entendez parler d’une fermeture ou d’un piratage, et vous vous dites : “Promis, demain je m’en occupe !”. Eh bien figurez-vous que demain, c’est aujourd’hui, maintenant, tout de suite, allez, pas d’excuse.
![]()
Dans ce guide, je vous explique :
- comment créer un cold storage, pour sécuriser vos bitcoins
- comment créer un wallet en watching-only, pour consulter votre portefeuille et recevoir des bitcoins sans risque, depuis votre ordinateur / tablette / téléphone
- comment signer des transactions, pour retirer des bitcoins de votre cold storage
Vous avez besoin :
- d’un ordinateur (sous Windows, macOS ou Linux)
- d’un lieu calme, à l’abri des regards
- d’une clé USB d’au moins 2 Go
- d’un morceau de papier et d’un stylo
- d’une heure de libre
Chaque étape est détaillée et illustrée, rassurez-vous, la procédure est bien plus simple et rapide (1 h maximum) que la longueur de cet article pourrait le laisser présager !
Créer un cold storage avec Electrum
Un cold storage ? Qu’est-ce que c’est ?
Un cold storage est un wallet qui n’a jamais été exposé à internet. L’objectif est de le rendre inaccessible à un pirate.
Pourquoi ne pas simplement me déconnecter d’internet avant d’accéder à mon wallet ?
Ce n’est pas suffisant ! Les logiciels espions s’accommodent très bien d’une coupure d’internet, ils gardent en mémoire ce qui s’affiche à votre écran et ce que vous tapez au clavier puis l’envoient au pirate lorsque vous vous reconnectez.
Mais mon ordinateur est sûr, je fais attention, je n’ai jamais eu de virus !
On parie tous vos bitcoins ? Le temps des virus visibles et destructeurs est révolu. Le piratage est devenu une véritable industrie, gérée par de grands groupes mafieux. Ces criminels disposent de ressources colossales et sont prêts à acheter des failles de sécurité pour des montants faramineux, car obtenir l’accès prolongé à l’ordinateur d’un particulier est très rentable : récupération d’informations bancaires, d’identifiants en tout genre (Netflix, Spotify, Amazon, etc.), envoi massif de spams, attaques distribuées, utilisation de la machine comme proxy, utilisation des capacités de calcul (pour miner des cryptos par exemple ?), et bien sûr vol de wallets !
Au-delà des virus, Windows et macOS sont de complexes boîtes hermétiquement fermées, sur lesquelles sont installées d’autres boîtes tout aussi hermétiques, et qui font peut-être bien d’autres choses que celles qu’on leur demande. Elles laissent (volontairement ou non) fuiter tout un tas d’informations à notre insu.
Pour toutes ces raisons, quelles que soient les précautions que nous pouvons prendre, il est impossible d’affirmer qu’un wallet est raisonnablement sûr sur un ordinateur connecté à internet.
Bon, mais les plateformes sont fiables, non ?
Pas vraiment :
- Coincheck : s’est fait dérober 523 millions de XEM (environ 530 millions de dollars) le 26 janvier 2018.
- MtGox : 951 116 bitcoins piratés en 2014.
- Bitfinex : s’est fait pirater 120 000 bitcoins en août 2016.
- Bithumb : les données personnelles de 31 800 utilisateurs ont été compromises et plusieurs milliards de wons auraient été dérobés sur le plus gros échange de Corée du Sud en juin 2017.
- MyBitcoin : fournisseur de wallets en ligne, a disparu de la surface du web en août 2011 avec 79 000 bitcoins .
- Iotaseed : fournisseur de wallets IOTA en ligne, a disparu de la surface du web avec l’équivalent de 3.94 millions de dollars en IOTA le 19 janvier 2018.
- Bitcoinica : s’est fait dérober 46 703 bitcoins en mars 2012 puis 18 000 bitcoins en mai 2012.
- Bitfloor : s’est fait pirater 24 000 bitcoins en septembre 2012 et a fermé en avril 2013.
- BTC-e : a fermé le 26 juillet 2017, les bitcoins volés sur MtGox, Bitcoinica, et Bitfloor ont transité par cet échange.
- Bitstamp : s’est fait dérober 19 000 bitcoins en janvier 2015.
- BTER : s’est fait pirater 7 170 bitcoins en février 2015.
- Picostocks : s’est fait voler 6 000 bitcoins fin novembre 2013.
- Inputs.io : fournisseur de wallet en ligne, s’est fait voler 4 100 bitcoins le 7 novembre 2013.
- Youbit: s’est fait dérober 17% des actifs de ses clients puis a fermé le 19 décembre 2017, ils s’étaient déjà fait pirater 4 000 bitcoins en avril 2017.
- Mintpal : s’est fait voler 3 700 bitcoins en décembre 2014.
- Kipcoin : s’est fait voler 3 000 bitcoins en février 2015.
- BIPS : fournisseur de wallet en ligne, s’est fait voler 1 295 bitcoins le 17 novembre 2013.
- Flexcoin : a fermé après s’être fait voler 896 bitcoins le 3 mars 2014.
- Bitcoin Savings and Trust : plateforme qui promettait 7 % de retour sur investissement par semaine par un système pyramidal. A fermé en août 2012 après avoir obtenu 764 000 bitcoins .
Je n’ai pas tout listé !
Avec l’envolée du cours des cryptomonnaies et de leur nombre d’utilisateurs, les plateformes d’échange sont devenues des cibles majeures de piratage. Vous ne devez y laisser que le strict minimum.
C’est contraignant ?
La sécurité vient souvent au détriment de la commodité. Mais l’idée n’est pas de ne rien laisser sur les plateformes et sur le wallet que vous utilisez au quotidien. Il s’agit de séparer votre épargne de votre compte courant. Gardez un montant raisonnable facilement accessible pour un usage régulier, et mettez le reste à l’abri.
C’est quoi Electrum ?
Electrum est un wallet bitcoin open source (licence MIT) et multiplateforme (Android, Windows, macOS, Linux) créé par Thomas Voegtlin en novembre 2011. Il est écrit en Python, un langage relativement simple, de plus, son code source est court ce qui le rend facile à auditer. Le projet est toujours très activement maintenu par son créateur et 193 contributeurs.
Ses caractéristiques principales :
- Wallet protégé : le fichier dans lequel votre clé est enregistrée est chiffré en AES-256-CBC. Un voleur ne peut rien en faire sans le mot de passe.
- Génération de clé déterministe : si vous perdez votre wallet, vous pouvez le récupérer à partir de sa seed. Vous êtes protégé de vos propres erreurs.
- Démarrage immédiat : le client ne télécharge pas les 152 Go de la blockchain, il demande cette information à un serveur. Pas de retards, toujours à jour.
- Transactions signées localement : Vos clés privées ne sont pas partagées avec le serveur. Vous n’avez pas à faire confiance au serveur.
- Liberté et confidentialité : le serveur ne stocke pas de comptes utilisateurs. Vous n’êtes pas liés à un serveur particulier et il n’a pas besoin de vous connaître. Vous pouvez exporter vos clés privées.
- Aucun script : Electrum ne télécharge aucun script. Un serveur compromis ne peut pas vous envoyer de code malveillant et voler vos bitcoins.
- Pas de SPOF (point unique de défaillance) : le code du serveur est open source, n’importe qui peut créer un serveur.
- Pas de pare-feu à configurer : Le client n’a pas besoin d’ouvrir de port particulier, il interroge simplement le serveur en HTTPS pour les mises à jour.
Mais au fait, t’es qui toi ?
Je m’appelle Blaise Thirard, j’ai 29 ans, je suis entrepreneur et j’ai une formation d’ingénieur système en informatique.
Lorsque j’ai découvert Bitcoin, son cours était d’environ 8 €. Quelques mois plus tard, j’en ai acheté plusieurs, que j’ai rapidement perdus lorsque la plateforme sur laquelle je les avais laissés a brutalement fermé.
J’ai depuis eu l’occasion de méditer sur l’intérêt de ne pas remettre au lendemain la sécurisation de ses cryptos !
On y va ?
Étape 1 : formater la clé USB
Formatez votre clé USB en FAT32 (les données qu’elle contient seront effacées) et laissez-la branchée à votre machine.
Si vous ne savez pas comment formater votre clé USB, je vous invite à suivre ce guide.
Étape 2 : Télécharger UNetbootin
Afin de créer notre clé USB amorçable, téléchargez puis lancez l’application UNetbootin : http://unetbootin.github.io/
UNetbootin est un petit logiciel permettant d’installer un système d’exploitation sur une clé USB. De cette façon, vous pourrez utiliser un autre système sans affecter votre ordinateur (vous retrouverez votre système habituel en retirant la clé USB).
Étape 3 : Créer une clé Ubuntu bootable
Nous allons utiliser la populaire distribution Ubuntu dans sa version 16.04 LTS. Dans les menus déroulants, choisissez Ubuntu et 16.04_Live. Puis, en bas de la fenêtre, ajoutez un espace de 500 Mo et assurez-vous que la lettre du lecteur correspond à votre clé USB, puis cliquez sur OK.

Le téléchargement et l’extraction de la distribution peut prendre un certain temps, mais ils ne nécessitent plus d’intervention de votre part, c’est le bon moment pour aller vous faire un café 😃.
Sous Windows, il peut arriver qu’UNetbootin se fige quelques instants, il retrouvera ses esprits à la fin de la copie des fichiers.
Étape 4 : Booter sur la clé USB
Vous pouvez maintenant redémarrer depuis votre clé USB amorçable. Si vous ne savez pas comment faire, je vous invite à consulter ce guide.
Attention, après avoir démarré sur votre clé USB amorçable, vous n’aurez plus accès à internet jusqu’à l’étape 8. Si vous n’avez pas de smartphone / tablette / ordinateur disponible pour poursuivre la lecture de ce guide pendant cet intervalle, je vous conseille d’imprimer les étapes 5 à 8.
Étape 5 : Démarrer Ubuntu
Dans le menu qui apparaît, sélectionnez la ligne Try Ubuntu without installing grâce aux touches directionnelles de votre clavier, puis validez avec la touche Entrée.
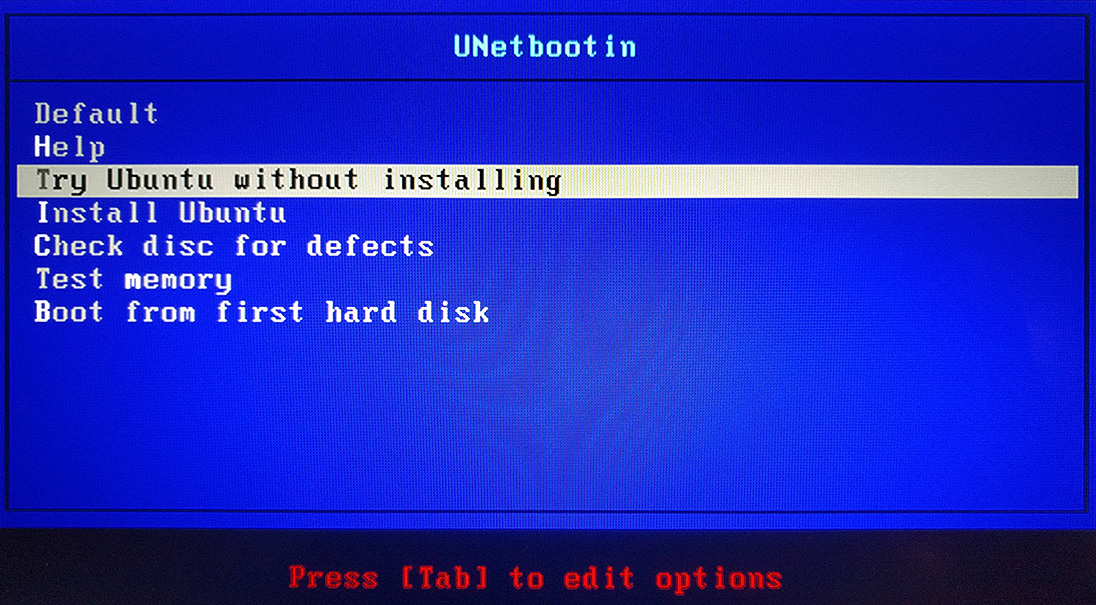
Vous êtes à présent sous Ubuntu !

Étape 6 : Configurer le clavier
Si vous utilisez un clavier qwerty, vous pouvez passer à l’étape 7.
Sinon, vous devez configurer Ubuntu pour votre clavier français. Pour cela, dans le coin supérieur droit, cliquez sur l’icône EN. Puis cliquez sur Text Entry Settings...

Ajoutez votre clavier français en cliquant sur le bouton +, puis French, puis Add.
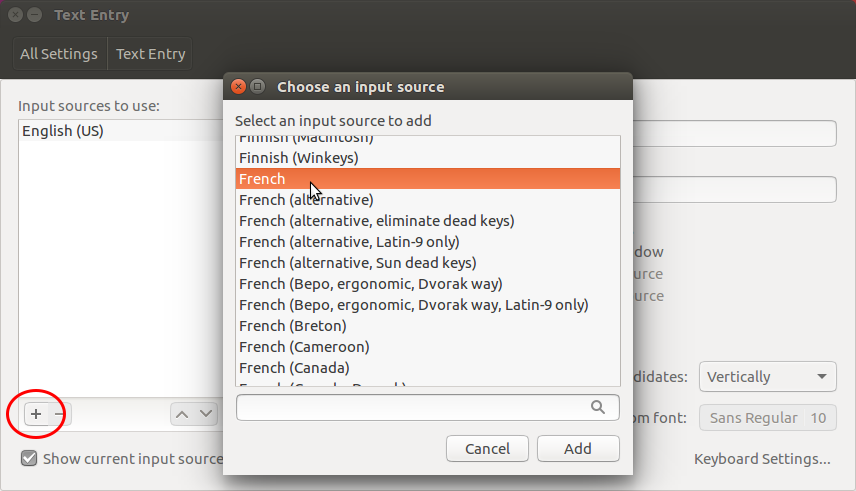
Sélectionnez le clavier anglais puis cliquez sur le bouton - pour le supprimer.

La configuration du clavier est terminée, vous pouvez fermer cette fenêtre en cliquant sur la petite croix rouge en haut à gauche de la fenêtre.
Étape 7 : Configurer le WiFi
Si votre ordinateur est connecté à internet par un câble Ethernet, vous pouvez directement passer à l’étape 8.
Sinon, connectez-vous à votre réseau WiFi en cliquant sur l’icône dans le coin supérieur droit.

Étape 8 : Récupérer le guide
Le menu vertical de gauche permet d’accéder aux logiciels installés. Lancez le navigateur Firefox, puis rouvrez le guide : https://blog.blaisethirard.com/creer-un-cold-storage-un-watching-only-wallet-et-signer-des-transactions-bitcoin-avec-electrum (ne vous ennuyez pas à taper l’adresse entière, les mots clés blog blaise thirard devraient suffire à Google pour vous ramener ici).

Étape 9 : Télécharger Electrum
Nous allons maintenant nous rendre sur le site de l’éditeur d’Electrum afin d’en télécharger la dernière version : https://electrum.org/#download
Dans la section Installation from Python sources, à la ligne Linux, cliquez sur le lien de téléchargement.

Faites OK pour ouvrir directement le gestionnaire d’archives.

Cliquez sur Extract pour décompresser Electrum dans votre répertoire personnel.

Cliquez de nouveau sur Extract puis sur Show the files.


Étape 10 : Installer Electrum
Electrum est écrit en Python, un langage de programmation libre, multiplateforme et polyvalent. Nous allons devoir installer les modules Python nécessaires à son fonctionnement. Pour cela, faites clic droit sur le répertoire Electrum-3.0.3, puis Open in Terminal.

Copiez-collez les 3 lignes de commande suivantes dans la console puis faites Entrée (pour coller dans la console, faites ctrl + maj + v, ou faites clic droit puis Paste).
sudo add-apt-repository universe && sudo apt-get update && sudo apt-get install -y python3-setuptools python3-pyqt5 python3-pip dirmngr
- La première ligne va ajouter le dépôt universe aux sources de logiciels Ubuntu. C’est un dépôt officiel maintenu par la communauté qui contient des paquets libres nécessaires à l’installation d’Electrum.
- La seconde ligne va mettre à jour la liste des dépôts APT avec le contenu du nouveau dépôt.
- La troisième ligne va installer les paquets complémentaires nécessaires.
Lorsque l’installation sera terminée, le contenu du terminal arrêtera de défiler et vous récupérerez l’invite de commande.

Electrum est dès à présent en état de fonctionner !
Étape 11 : Désactiver internet
Avant de lancer Electrum, nous allons nous déconnecter d’internet.
Si votre ordinateur est connecté par un câble Ethernet, débranchez-le. Si vous êtes connecté en WiFi, il va également falloir le désactiver. Pour cela, cliquez sur l’icône en haut à droite et décochez Enable Wi-Fi.

Comme c’est important, nous allons nous assurer que votre ordinateur est bien déconnecté d’internet. Pour cela, retournez dans le terminal, et entrez la commande suivante puis faites entrée :
ping -c 3 8.8.8.8
Si vous obtenez le message connect: Network is unreachable, c’est parfait. Sinon, cela signifie que vous êtes toujours connecté à internet, assurez-vous que le câble est correctement débranché et que vous avec bien déconnecté le WiFi.

Étape 12 : Créer un cold-wallet bitcoin
Nous pouvons enfin lancer Electrum afin de créer notre cold wallet ! Pour cela, dans la console, entrez la commande suivante et faites Entrée :
python3 electrum & sudo gedit /cdrom/pub-key.txt &
python3 electrum &: cette commande va lancer Electrumsudo gedit /cdrom/pub-key.txt &: cette commande va lancer un éditeur de texte avec les droits d’écriture nécessaires pour enregistrer le fichierpub-key.txtà l’emplacement/cdrom. Ce fichier nous permettra de sauvegarder la master public key lors de l’étape 13.
Au premier lancement, Electrum va vous demander à quel serveur vous souhaitez vous connecter. Cela ne nous intéresse pas, puisque nous sommes hors ligne. Laissez le choix par défaut et faites Next.

Electrum vous propose de choisir le nom de votre wallet. Nous pouvons laisser le nom par défaut puisque nous ne le conserverons pas.
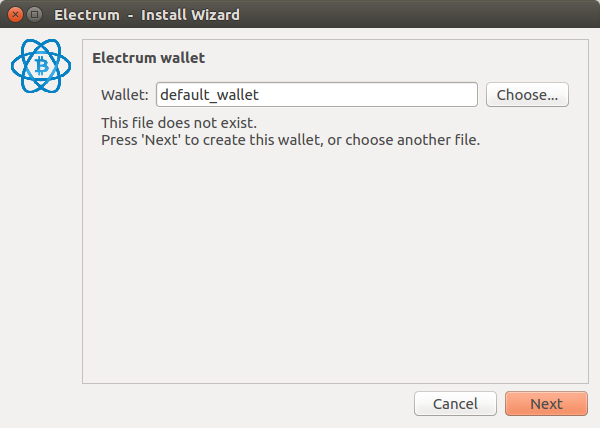
Electrum propose plusieurs options avancées, nous allons créer un wallet standard.
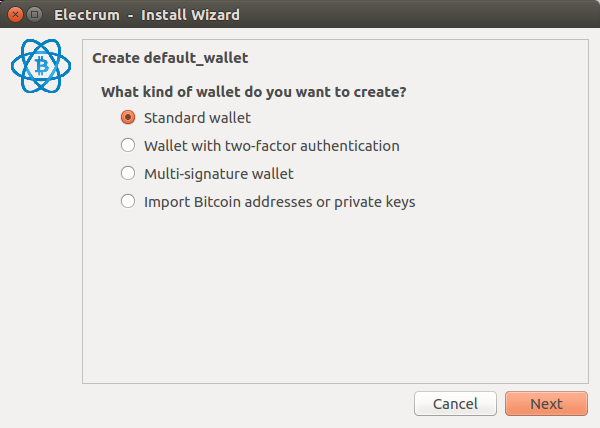
Nous allons créer une nouvelle seed. La seed est une phrase aléatoire utilisée pour générer la clé privée de notre wallet.

Electrum est probablement le premier wallet à supporter nativement les adresses segwit. Segwit est une mise à jour qui apporte un certain nombre d’améliorations, vous trouverez plus d’informations ici. Malheureusement, en raison de sa jeunesse, la plupart des wallets, brokers et plateformes d’échange ne supportent pas encore ces adresses.
Pour être précis, si vous créez une adresse segwit, vous pourrez recevoir des bitcoins depuis des wallets Electrum (version 3.0 ou supérieure) et en envoyer à tous les wallets, échanges et brokers. Mais vous ne pourrez pas recevoir de bitcoins en provenance de la plupart des autres wallets, échanges et brokers, car ils ne supportent pas encore ce type d’adresses. Pour cette raison, je vous recommande de ne pas créer d’adresse segwit aujourd’hui.
Laissez l’option Standard et cliquez sur Next.

ATTENTION, LISEZ ATTENTIVEMENT CE QUI SUIT !
Le moment est venu de sortir votre papier et votre stylo. Vous devez recopier votre seed en veillant à ne pas faire de fautes, et à écrire lisiblement.
Faites attention au support sur lequel vous vous appuyez. Évitez les calendriers et les blocs-notes qui laissent des traces. Imprimer votre seed est une mauvaise idée, car les imprimantes peuvent garder en mémoire les derniers documents imprimés. Nous verrons comment sauvegarder votre seed sur le long terme à l’étape 16.
Si vous égarez cette suite de mots, vos bitcoins sont définitivement perdus, il n’existe absolument aucun moyen de récupération.
Lorsque vous avez recopié votre seed, vous pouvez poursuivre en cliquant sur Next.

Vous devez retaper votre seed. Ne faites pas de copier-coller, l’objectif est de s’assurer que vous n’avez fait aucune erreur lorsque vous l’avez notée.

Lorsqu’Electrum génère un wallet, il enregistre votre seed et votre private key dans un fichier sur votre machine, ce qui est dangereux. Pour limiter les risques, nous allons lui demander de chiffrer ce fichier en AES-256-CBC afin de le rendre illisible.
Comme nous avons noté la seed, nous pourrons régénérer notre wallet à volonté, ce fichier nous est donc inutile. Entrez un mot de passe fort, par exemple 4 mots aléatoires, vous n’aurez jamais à vous en souvenir.

Voilà, vous avez sous les yeux votre wallet. Rien ne s’y affiche puisque vous n’avez pas encore fait de transaction et que vous n’êtes pas connecté à internet.

Étape 13 : Récupérer la clé publique
Avant d’éteindre l’ordinateur, nous allons récupérer la master public key. Cette clé va nous être utile pour créer notre wallet en lecture seule, c’est-à-dire un wallet dont on peut consulter l’historique des transactions et vers lequel on peut envoyer des bitcoins, mais depuis lequel il est impossible de retirer des bitcoins. Cette clé n’est donc pas sensible comme votre seed, mais vous devez garder à l’esprit que quiconque la possède a la possibilité de consulter l’historique de vos transactions et de savoir combien de bitcoin vous possédez.
Partager cette clé revient à diffuser vos relevés bancaires, à la différence que la sécurité de votre compte bancaire est assurée par une banque. Si vous ne souhaitez pas vous faire braquer comme ce couple d’Anglais, ni enlever comme cet Américain ou ce PDG d’une plateforme d’échange anglaise, je vous recommande ne pas faire étalage du contenu de votre wallet. Même si cela ne représente pas grand-chose aujourd’hui, il se pourrait que sa valeur augmente considérablement demain.
Dans Ubuntu, le menu des applications apparaît dans la barre des tâches lorsque celle-ci est survolée.

Pour récupérer la master public key, rendez-vous sur Wallet puis cliquez sur Information.

La suite de caractères qui s’affiche est votre master public key, cliquez sur l’icône en bas à droite de la fenêtre pour la copier dans votre presse-papier.

La ligne de commande de l’étape 13 a ouvert Electrum ainsi qu’un éditeur de texte. Retournons dans l’éditeur de texte.

Faites ctrl + v ou clic droit Paste pour coller la master public key, cliquez sur Save, puis cliquez sur la croix rouge en haut à gauche de l’éditeur pour le fermer.
 Étape 14 : Effacer ses traces
Étape 14 : Effacer ses traces
Il ne nous reste plus qu’à effacer nos traces et éteindre l’ordinateur. Pour cela, nous allons commencer par fermer Electrum. Faites clic droit sur l’icône d’Electrum puis Quit.
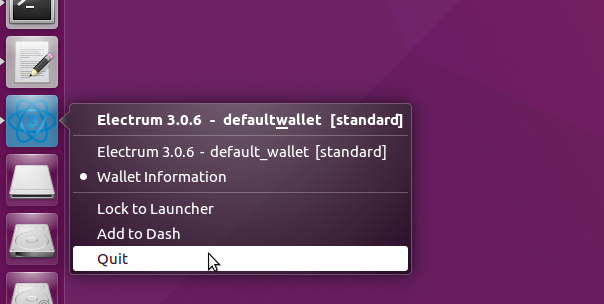
Ensuite, retournez dans la console, copiez-collez les commandes suivantes et faites Entrée (si vous ne voyez pas la ligne de l’invite de commande, cela signifie que vous n’avez pas fermé Electrum ou l’éditeur de texte).
cd /; sudo su rm -rf /home/ubuntu/Electrum* rm -rf /home/ubuntu/.electrum cat /dev/zero > zero.file
- La première commande permet de se placer à la racine d’Ubuntu et de prendre les droits administrateur.
- Les 2 suivantes permettent de supprimer le répertoire qui contient Electrum ainsi que le répertoire dans lequel il a enregistré le fichier chiffré dont nous avons parlé tout à l’heure.
- Comme vous le savez sans doute, lorsqu’on supprime un fichier, le système d’exploitation se contente de dire que l’espace disque est redevenu disponible, mais il reste présent jusqu’à ce qu’il soit écrasé par un autre fichier. Cette commande permet de créer un fichier que l’on va remplir de zéros jusqu’à ce qu’il n’y ait plus de place disponible sur le support de stockage. De cette façon, nous sommes sûrs que tous les morceaux de fichiers précédemment enregistrés ont été écrasés — sur une clé USB, une seule passe est suffisante, car il n’existe pas de rémanence magnétique résiduelle.
Lorsque vous aurez entré les trois commandes suivantes, votre ordinateur s’éteindra. Vous pourrez débrancher votre clé USB, rebrancher votre câble Ethernet si vous l’aviez débranché, et redémarrer votre ordinateur normalement.
Copiez-collez les commandes suivantes et faites Entrée.
sync rm zero.file halt
- La première commande permet de s’assurer que notre fichier a été correctement écrit sur le support de stockage (il aurait pu rester en mémoire cache).
- La seconde commande permet de supprimer le fichier rempli de zéros que nous venons de créer.
- La dernière commande permet d’éteindre l’ordinateur.
Il se peut qu’au lieu de s’éteindre, votre ordinateur reste bloqué sur l’étape de chargement d’Ubuntu, dans ce cas, retirer votre clé USB et restez appuyé 5 secondes sur le bouton d’allumage de votre machine.
Étape 15 : Sauvegarder la clé publique
Vous lisez actuellement ce guide depuis votre ordinateur habituel.
Avant de passer à la suite, vous devez sauvegarder la clé publique que nous avons enregistrée dans le fichier pub-key.txt que nous avons placé à la racine de la clé USB.
Si vous perdez cette public key, ce n’est pas dramatique, car la seed (les 12 mots que vous avez soigneusement recopiés) vous permet de régénérer votre wallet, et donc de la retrouver, mais évitez-vous cette peine, gardez-la !
Nous l’avons vu à l’étape 13, cette clé permet de consulter votre wallet, enregistrez-la à des endroits auxquels vous seul avez accès (email, Dropbox, clé USB bien rangée, téléphone, etc.).
Étape 16 : Sauvegarder la seed Electrum
Faire un wallet super sécurisé c’est bien, à condition de ne pas en perdre l’accès ! Pour cela, il y a deux conditions à considérer :
- la pérennité de votre seed
- la pérennité d’Electrum
Assurer la pérennité de votre seed Electrum
Comme nous l’avons vu, si vous perdez votre seed, vous perdez vos bitcoins, et c’est irrémédiable. Il est donc important de la mettre en lieux sûrs. “Lieux” est au pluriel, car personne n’est à l’abri d’un incendie ou d’une inondation, vous devez conserver votre sauvegarde dans deux endroits physiquement distincts.
Aussi, afin de limiter les risques, vous ne devez pas écrire votre seed en entier sur vos sauvegardes, scindez-la en deux groupes de 6 mots. De cette façon, si quelqu’un venait à accéder à l’une des moitiés, il ne pourrait rien en faire sans disposer de l’autre.
Ci-dessous, quelques idées à adapter de lieux dans lesquels cacher vos 2 groupes de 6 mots :
- Le coffre-fort d’une banque (compter environ 100 € par an).
- Au dos d’une carte de visite, glissée dans un tube d’aspirine (les tubes d’aspirine possèdent un absorbeur d’humidité) que vous rangerez dans un endroit improbable (au fond du congélateur, dans une boite de bâtonnets Croustibat® ? Dans un pot de cactus ? Oui, ça pique, justement :D). Veillez à bien rincer puis sécher l’intérieur du tube (l’aspirine est acide). Non, le placard à pharmacie de la salle de bain n’est pas une bonne cachette, la salle de bain est le premier endroit visité par des cambrioleurs à la recherche d’argent liquide.
- Sur la tranche supérieure ou inférieure d’une des portes intérieures de la maison (n’allez pas vous faire mal hein !).
- Un livre de votre bibliothèque (attention le jour où vous faites un vide-grenier !).
- Un fin morceau de papier glissé derrière l’étiquette d’un flacon de Canard WC® (l’étiquette des flacons Canard WC® n’est pas collée à la bouteille, il s’agit d’un cerclage en plastique qui a été rétracté thermiquement, il est donc facile d’y glisser quelque chose). Rangez le flacon avec les autres, mais veillez à ne pas l’utiliser afin qu’il ne termine pas à la poubelle…
- Un poème dans lequel vous utilisez 6 mots de votre seed (attention vous devrez être capable de retrouver les 6 mots utiles dans le bon ordre).
- Un document quelconque, noyé parmi vos papiers administratifs.
- Un papier glissé dans une des peluches du petit dernier (je sais, vous n’aviez pas prévu de faire de la couture aujourd’hui…).
- Un petit bout de papier, glissé dans une de vos dizaines de boules de Noël (certaines se décollent en 2, d’autres sont souples et permettent de faire une légère incision, et pour les rigides, il est parfois possible de décoller le support de l’anneau de fixation afin de faire un petit trou en dessous puis le recoller).
- Un petit bout de papier, glissé dans le couvercle d’une bombe aérosol d’entretien que vous rangerez sous l’évier, dans le garage, le grenier ou la cave (attention à l’humidité et au ménage de printemps…).
- Au milieu d’un sachet de pâtes alimentaires qui restera au fond d’un placard (attention aux fringales au retour de soirées arrosées…).
Vous avez séparé votre seed en deux, et vous avez bien caché ces deux groupes de 6 mots. Maintenant, afin de se prémunir d’un dégât matériel important, il faut confier de nouvelles sauvegardes à deux personnes qui ne se connaissent pas (et qui n’habitent pas juste à côté). Je vous laisse leur expliquer pourquoi il faut absolument qu’ils conservent précieusement un flacon de Canard WC®…
Si vous avez le moindre doute sur l’intégrité de votre seed, si quelqu’un en qui vous n’avez pas confiance a eu accès à l’une des moitiés de votre sauvegarde, créez immédiatement un nouveau cold storage, et transférez-y vos bitcoins.
Assurer la pérennité d’Electrum
Electrum est un des wallets Bitcoin les plus populaires, il n’y a donc aucune chance qu’il disparaisse sur le court terme. Cependant, dans plusieurs années, certains événements pourraient compliquer l’accès à vos bitcoins (changement majeur de version, arrêt du support, décès du développeur, etc.).
Je vous conseille de vous renseigner au moins 1 fois par an sur les évolutions d’Electrum. En cas de changement important de version, il vous suffira de créer un nouveau wallet et de transférer vos bitcoins dessus.
Dans ce guide, nous installons Electrum sur la version LTS d’Ubuntu (long term support), cela signifie que son support est assuré jusqu’en avril 2021. Si Electrum venait à disparaître de la surface du web d’ici là (improbable) et que vous en avez conservé les sources, vous pourrez le réinstaller sans le moindre problème.
Vous pouvez récupérer les sources d’Electrum à l’adresse suivante : https://github.com/spesmilo/electrum/archive/master.zip
Créer une version watching-only de votre wallet Electrum
Un watching-only wallet ? Qu’est-ce que c’est ?
Un wallet en lecture seule est un wallet connecté à internet qui vous permet de recevoir des bitcoins, de consulter l’historique complet des transactions qui ont eu lieu sur votre cold storage, mais qui ne peut pas signer de transaction.
Cela rend donc impossible le retrait de bitcoins directement depuis un watching-only wallet. De cette façon, depuis votre téléphone ou votre ordinateur habituel, vous pouvez très simplement alimenter et consulter votre cold storage sans en compromettre la sécurité.
Étape 1 : Installer Electrum
Installer Electrum sur un appareil Android
Vous pourrez installer la version Android officielle d’Electrum directement depuis le Google Play Store en cliquant sur le lien suivant : https://play.google.com/store/apps/details?id=org.electrum.electrum ou en recherchant Electrum Bitcoin Wallet depuis votre appareil Android.
Installer Electrum sur Windows
Pour installer Electrum sur votre ordinateur Windows, rendez-vous sur le site officiel : https://electrum.org/#download
Dans la section Easy installation, cliquez sur Windows Installer puis suivez les étapes habituelles d’installation.
Installer Electrum sur macOS
Pour installer Electrum sur votre Mac, rendez-vous sur le site officiel : https://electrum.org/#download
Dans la section Easy installation, cliquez sur Executable for OS X puis suivez les étapes habituelles d’installation.
Installer Electrum sur Ubuntu, Debian ou Raspbian
Pour installer Electrum sous Linux, rendez-vous sur le site officiel : https://electrum.org/#download
Suivez la procédure décrite dans la section Easy installation.
Si vous rencontrez des difficultés pour installer les dépendances, ajoutez le dépôt universe avec la commande suivante :
add-apt-repository universe && apt-get update
Étape 2 : Créer un watching-only wallet
Lancez Electrum et laissez le choix par défaut puis faites Next.

Electrum vous propose de choisir le nom de votre wallet. Libre à vous de le modifier ou de laisser celui par défaut.

Electrum propose plusieurs options, nous allons rester sur Standard wallet.
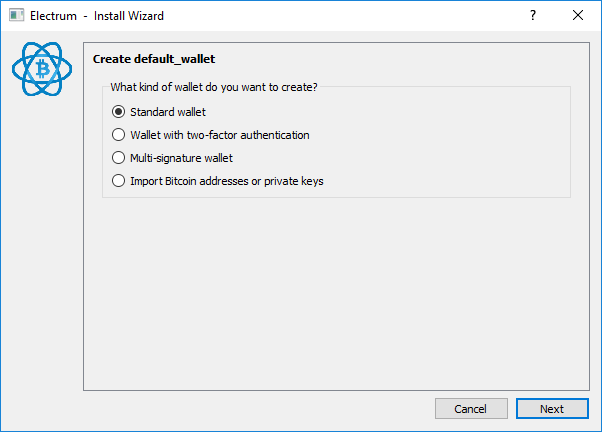
Sélectionnez l’option Use public or private keys.

Le moment est venu d’utiliser la master public key de notre cold storage que nous avons sauvegardée tout à l’heure, entrez-la dans le champ texte puis faites Next.
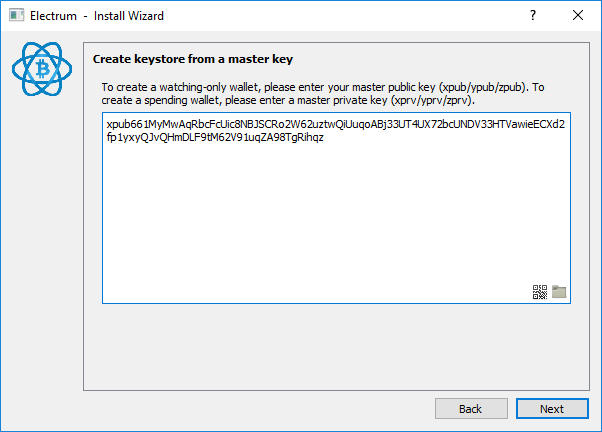
La création de votre watching-only wallet est terminée, Electrum vous affiche le message d’alerte suivant :
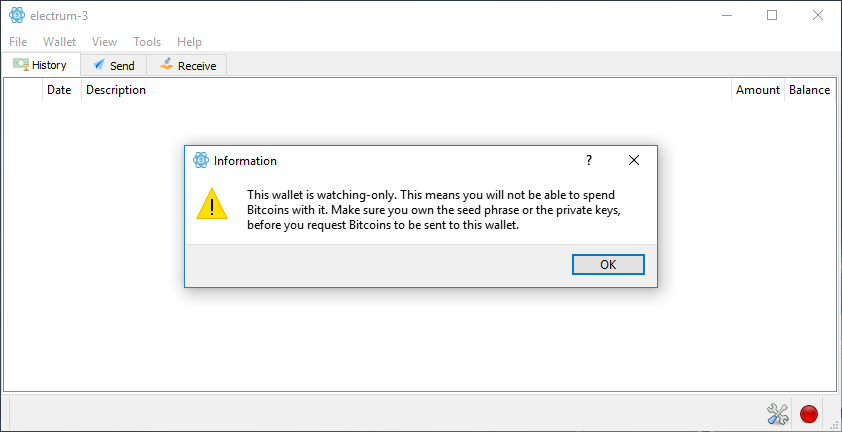
Ce wallet est en lecture seule. Cela signifie que vous ne serez pas en mesure de dépenser des bitcoins avec. Assurez-vous de posséder la seed ou les clés privées avant de demander l'envoi de bitcoins vers ce wallet.
C’est une sage recommandation ! Assurez-vous d’avoir mis votre seed en lieux sûrs avant d’envoyer des bitcoins vers votre cold storage.
Présentation de l’interface
Par défaut, Electrum propose trois onglets :
- History : affiche l’historique des transactions depuis la création de votre cold storage.
- Send : vous permet d’envoyer des bitcoins — cependant, comme votre wallet est en watching-only, la transaction n’aboutira pas, car elle ne sera pas signée. Nous verrons comment signer une transaction depuis votre cold storage dans la section “
Signer une transaction, pour retirer des bitcoins de votre cold storage“. - Receive : affiche l’adresse vers laquelle envoyer les bitcoins pour les déposer sur votre cold storage.
En bas à gauche, vous pouvez voir la balance de votre cold storage. Par défaut, celle-ci s’affiche en milliBitcoin. Si vous le souhaitez, vous pouvez changer le préfixe d’unité dans les paramètres, accessibles via l’icône située en bas à droite.

Déposer des bitcoins sur votre cold storage
Pour cela, rien de plus simple, rendez-vous dans l’onglet Receive.

La ligne Receiving address affiche l’adresse à donner à la personne ou à la plateforme depuis laquelle les bitcoins doivent êtres envoyés.
Par mesure de sécurité, cette adresse change à chaque fois qu’elle a été utilisée pour recevoir des bitcoins . Cependant, rien n’empêche d’utiliser une même adresse plusieurs fois.
Lorsque vous envoyez des bitcoins vers votre cold storage, la transaction peut mettre plusieurs minutes à s’afficher et plusieurs heures à être validée.
Si vous n’êtes pas familier avec le transfert de bitcoins , je vous suggère de commencer par ne transférer qu’un petit montant. Cependant, n’oubliez pas que chaque transaction entraîne des frais !
Signer une transaction, pour retirer des bitcoins de votre cold storage
Afin de retirer des bitcoins de votre cold storage, vous devez émettre une transaction signée. Or, comme nous l’avons vu, notre watching only wallet n’est pas capable de signer les transactions.
La procédure à suivre est donc la suivante :
- générer une transaction non signée depuis notre watching only wallet connecté,
- signer cette transaction hors ligne depuis notre cold storage
- diffuser la transaction signée depuis notre watching only wallet connecté.
Étape 1 : Générer une transaction non signée
Depuis votre watching only wallet connecté, rendez-vous dans l’onglet Send.
Dans le champ Pay to, entrez l’adresse vers laquelle vous souhaitez envoyer les bitcoins. Le champ Description est facultatif, il vous permet d’enregistrer des informations supplémentaires sur la transaction ; ces informations ne seront visibles que depuis votre watching only wallet et ne serons pas communiquées au destinataire de la transaction. Le champ Amount vous permet de définir le montant à envoyer, n’oubliez pas que par défaut, l’unité est le milliBitcoin. Comme vous le savez, chaque transaction en bitcoin entraîne des frais, le champ Fee vous permet d’en définir le montant. Notez que plus les frais sont bas, plus la transaction est longue à être exécutée. Si vous ne savez pas quelle valeur mettre, je vous recommande de laisser celle suggérée par Electrum.

Cliquez sur Preview, à la ligne Fee, vérifiez le montant des frais, puis dans la section Outputs, assurez-vous que l’adresse et le montant indiqués sur la ligne surlignée en vert sont corrects et que l’adresse de destination est la bonne (il existe des virus qui changent l’adresse de destination lorsque vous faites un copier-coller). Si tout est bon, cliquez sur Save pour sauvegarder la transaction sur votre ordinateur.
![]()
Vous vous demandez peut-être à quoi correspondent les valeurs dans les champs Inputs et Outputs. C’est très simple, je souhaite envoyer 100 mBTC à l’adresse 1PhAJ7RqbVCYqWnayUMTrwTpXhwcJgESbh et cette transaction va me coûter 0.872 mBTC de frais. Comme je n’ai jamais reçu de transaction de ce montant exact, il va falloir en regrouper plusieurs afin que leur somme atteigne au minimum 100.872 mBTC. Ici, une transaction de 54.64 mBTC ainsi qu’une autre de 58.67 mBTC ont été sélectionnées. Je vais envoyer 54.64 + 58.67 = 113.31 mBTC au lieu de 100.872 mBTC. On va donc me rendre la monnaie : 113.31 – 100.872 = 12.438, c’est le montant que vous pouvez voir sur la ligne jaune du champ Outputs.
Étape 2 : Régénérer votre cold wallet pour signer une transaction
Afin de signer votre transaction, vous devez régénérer votre cold wallet à partir de la seed que vous avez précieusement notée quelque part.
Pour cela, suivez les étapes 1 à 3 (comprise) de la section Créer un cold storage avec Electrum. Ensuite, copiez votre transaction non signée à la racine de la clé USB (si vous avez laissé le nom par défaut, le fichier s’appelle unsigned.txn), puis continuez avec les étapes 4 à 11 (comprise).
Dans la console, entrez la commande suivante et faites Entrée pour lancer Electrum :
python3 electrum & sudo gedit /cdrom/signed.txn &
Laissez le choix par défaut et faites Next.
Laissez le nom par défaut et faites Next.
Laissez l’option Standard wallet sélectionnée et faites Next.
Sélectionnez l’option I already have a seed et faites Next.

Entrez les 12 mots qui composent votre seed puis faites Next. Si le bouton Next n’apparaît pas, cela signifie que vous avez fait une faute de frappe.

Entrez un mot de passe fort, par exemple 4 mots aléatoires (vous n’aurez à vous en souvenir que pendant la minute qui suit afin de signer la transaction) et faites Next.
Vous revoilà sur votre cold storage ! Comme vous vous en doutez, aucune information sur son activité ne peut s’afficher, car nous sommes hors ligne.
Cela ne nous empêche pas de pouvoir signer notre transaction. Pour cela, survolez la barre des tâches en haut à gauche afin de faire apparaître le menu d’Electum. Naviguez dans Tools, puis Load transaction et cliquez sur From file.
![]()
Il nous faut à présent ouvrir la transaction non signée que nous avons créée depuis notre watching-only wallet et copiée sur notre clé USB. Cliquez sur Computer, puis /, puis cdrom, puis sélectionnez le fichier unsigned.txn, enfin, cliquez sur Open.
![]()
![]()
![]()
Nous retrouvons notre transaction. Au cas où, on vérifie de nouveau que l’adresse de destination (surlignée en vert dans la section Ouputs) ainsi que le montant (sur la même ligne) sont les bons, puis on clique sur le bouton Sign.
![]()
Comme notre wallet est chiffré, vous devez entrer le mot de passe que vous avez temporairement créé.
Vous pouvez le constater à la ligne Status, notre transaction est désormais signée. Cliquez sur le bouton Copy situé en bas à gauche de la fenêtre.

Rendez-vous dans l’éditeur de texte qui s’est ouvert en même temps qu’Electrum lorsque nous avons entré la commande dans le terminal, puis faites ctrl + v ou clic droit Paste pour coller la transaction, puis cliquez sur Save.

Voilà, nous en avons terminé avec notre cold storage, je vous invite à présent à fermer Electrum et à effacer vos traces en suivant l’étape 14 de la section Créer un cold storage avec Electrum. Lors de sa fermeture, Electrum va vous informer que la transaction n’est pas enregistrée, ne vous en inquiétez pas, nous l’avons enregistrée directement sur notre clé USB.
Étape 3 : diffuser une transaction signée depuis un watching only wallet
Notre transaction étant signée, il ne nous reste plus qu’à la diffuser. Pour cela, depuis votre système habituel, lancez votre watching-only wallet Electrum.
Dans le menu d’Electum, naviguez dans Tools, puis Load transaction et cliquez sur From file. Naviguez vers la racine de votre clé USB et sélectionnez le fichier signed.txn dans lequel nous venons de sauvegarder la transaction signée, puis cliquez sur Open.
Vous retrouvez la transaction que nous venons de signer depuis notre cold storage. Pour la dernière fois, vérifiez que la transaction que vous venez de charger envoie le bon montant vers la bonne adresse, puis cliquez sur le bouton Broadcast afin de la diffuser.

Si cet article vous a aidé, n’hésitez pas à le partager aux personnes à qui il pourrait être utile. Vous pouvez également me remercier par un don PayPal, ou bitcoin à l’adresse ci-dessous :
1PhAJ7RqbVCYqWnayUMTrwTpXhwcJgESbh













